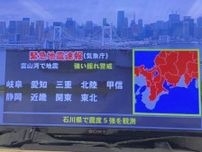
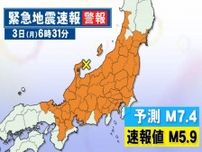
東京工業大や富士通などは10日、スーパーコンピューター「富岳」を活用し、文章などを自動で作る生成AI(人工知能)の基盤となる大規模言語モデル「Fugaku―LLM」を開発したと発表した。学習データの多くに日本語を用いており、国内のニーズに合わせた生成AIの研究につながることが期待される。
富岳を使った開発は2023年5月から開始され、東北大や名古屋大、理化学研究所なども参加した。学習データの約6割が日本語で、松尾芭蕉の俳句に関する質問にも流ちょうに回答できるなど、日本語能力に特化している点が特徴だ。
こうしたデータは開発に当たって独自に収集したもので、有害な文言をあらかじめ排除するなどした。このため学習の全過程を把握でき、海外のモデルと比べて透明性と安全性が向上したという。